La route ? Là où on va, il n’y a pas de route !

C’est précisément de voyage dans le temps que nous allons explorer ici ! Plutôt de versionning (mais promis, c’est tout pareil ! ).
Le versionning dans le développement c’est ton meilleur pote. Grâce à lui, tu n'as pas peur de faire des erreurs puisque ça peut être effacé (même 3 - 4 jours après et des milliers de lignes de code plus tard) à l’instant où tu as sauvegardé la dernière fois.
Et là tu vas me répondre : “Je peux faire du copier coller de dossiers”. Fin du game. Fin de l'article.
Tu as vraiment envie que tes répertoires ressemblent à ça ?
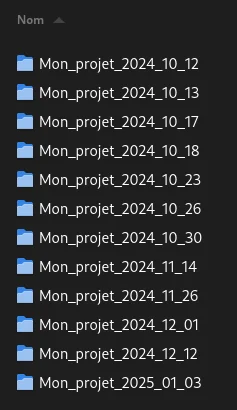
Pour éviter de devenir complètement cinglé, oublie vite cette idée. D’une part, c’est pas du tout pérenne dans le temps et d’autre part ton PC va exploser en poids avec autant de dossiers dupliqués. Pour éviter ça et avec l’aide de quelques commandes, tu auras la main sur tous les moments de ton code où tu auras décidé de dire “OK, là je sauvegarde”.
Mais quelle est donc cette sorcellerie ?! C’est Git et son compagnon Git/Hub/Lab/ea/Bucket … (il y a pas mal de concurrents qui ont tous leurs particularités).
Pour la démo, on va uniquement s’attarder sur le duo Git - Github.

Git c'est quoi ? C’est un gestionnaire de versions de fichiers créé par le génialissime Linus Torwarld (Le créateur de Linux … rien que ça !).
Git c'est le software qui permet à l’utilisateur de sauver son code, de changer la version à n’importe quel moment.
GitHub c’est l’hébergeur de code. Couplé à Git il permet d’externaliser sa codebase sur les serveurs de GitHub. On peut ainsi :
-
Sauver son code dans le cloud
-
Travailler en équipe
-
Voir le code d'autres développeurs (utile pour l'open source)
-
Créer des workflows pour du CI/CD (Pas de panique, on abordera pas cette notion ici)
Bref tu l'as compris, l'association Git-Github est ultra complémentaire et apporte des avantages non négligeables pour un développeur.
C'est aussi une partie un peu sensible parce que le versioning c'est un peu abstrait et technique au début. Mais pas de panique, on va voir la base ensemble !
1. Le principe de Git (et son jargon)
Utiliser Git c'est utiliser des termes comme "commit", "push", "branch", "merge". Ça va demander un peu d'efforts de ta part au début mais c'est comme tout, avec la pratique ça viendra tout seul ensuite.
Git c'est donc le C.L.I (Command Line Interface).
Et ce C.L.I va gérer localement tes repositories (tes dépôts).Un dépôt = un projet.
Chaque projet (donc chaque dépôt) contient plusieurs branches et dans ses branches plusieurs commits.
-
Une branche = une version de ton repository
-
Un commit = un instantané de cette version à un instant T
Pour illustrer sous forme de schéma un repo, voici ce que ça peut donner.
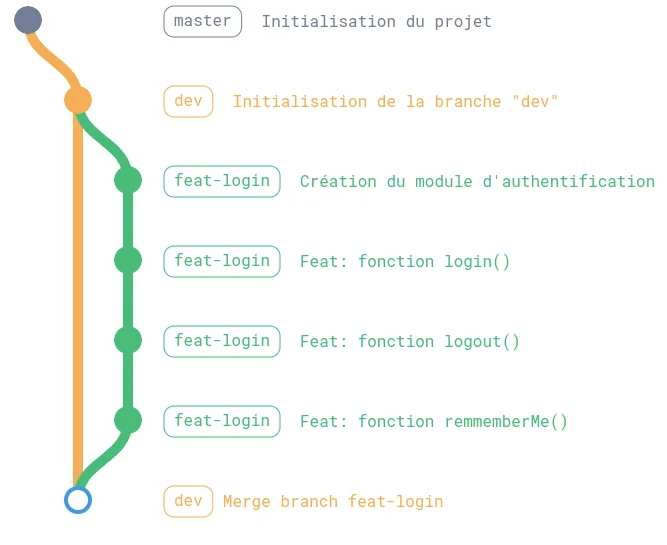
Chaque rond (nœud) est un commit (donc un instantané) contenant le message de cet instantané (pour qu’on puisse s’y retrouver dans la liste).
Chaque couleur est une branche dans la vie de notre projet.
Quand on commit, on avance de 1 nœud dans notre branche.
Quand on est satisfait de la branche et qu’on souhaite la fusionner avec la branche du dessus, on “merge” et on y met un message.
Beaucoup de termes mais avec la pratique ça deviendra naturel. J’arrête ici pour le principe, on va passer à la pratique !
2. Notre premier repository
Pour utiliser Git, tu vas installer Git Bash (le C.L.I) disponible ici (Si tu es sous linux, c'est inclus dans l'installation).
Ensuite on va créer un dossier dans notre système qui contiendra notre projet de tuto qu'on nommera "Tuto Git" (t'as vu un peu l'inspi ?!).
Tu ouvres ensuite Git Bash et tu te déplaces vers ton dossier depuis ton terminal (avec la commande "cd").
Une fois dedans tu fais cette commande pour initialiser ton repo : git init
(sous entendu git initialise mon nouveau dépôt stp !)
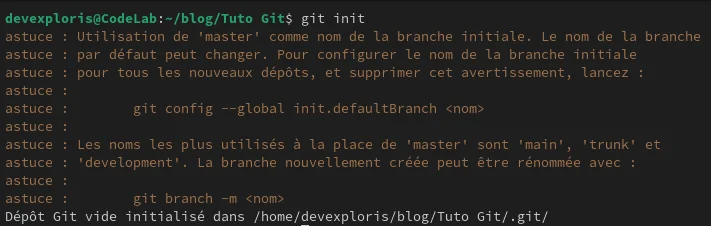
Git nous signale que l’on peut changer par défaut le nom de la branche qui est créée dès le début (utilise la commande qu’il te suggère pour paramétrer tes futurs repos et enlever le message).
La dernière ligne nous indique qu'un dossier ".git" qui contient l’ensemble des informations liées à Git pour le versionnage de notre projet (On aura pas besoin d’y toucher, juste de savoir que c’est ce dossier qui gère tout).
C’est donc le point de départ de notre dépôt.
Théoriquement si c’est ton premier commit, tu devras faire les commandes suivantes pour ajouter les informations de ton compte git :
-
git config --global user.email "tonNom@exemple.com" -
git config --global user.name "Ton Nom"
On ouvre maintenant notre projet avec un IDE et on crée une page HTML.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial- scale=1.0"> <title>Mon premier repo</title>
</head>
<body>
<h1>Nom de zeus !</h1>
</body>
</html>On a créé quelques lignes de code, on va maintenant sauver notre projet sur Git. Pour ça, on va faire notre premier commit :
-
git add . -
git commit -m "Feat: Création de la page index.html" -
git add .c’est une commande pour indiquer à Git quel(s) fichier(s) il va devoir gérer lors de ce commit. (ici, tout le répertoire courant : ".").
-m signifie “message” pour écrire le commentaire.
Pour les commits, il vaut mieux indiquer des messages clairs et précis comme “Ajout de la fonction ….” plutôt que “Mon commit trop cool”. Comme ça, quand on va lister les commits, on sait dès le commentaire à quoi correspond le commit.
Il existe une convention pour écrire les commits disponible ici.

Git détecte alors le nombre de fichiers changés (ici 1) et le nombre de lignes ajoutées / supprimées (11 insertions).
Le commit, en plus d’être caractérisé par un commentaire est aussi caractérisé par un sha256 (ici d68bf2a). Git se sert de ce sha pour se repérer dans la timeline de ton repository.
On a à présent sauvé notre première version de notre branche "master" avec notre premier commit.
Maintenant on va faire quelques modifications de notre fichier index.html en y ajoutant une liste d’items:
<ul>
<li>Item 1</li>
<li>Item 2</li>
<li>Item 3</li>
<li>Item 4</li>
<li>Item 5</li>
</ul>On crée un second commit :
git add .
git commit -m "Feat: Ajout de liste items"
On a donc sauvegardé dans git ce petit ajout.
A ce stade tu peux te demander quand tu dois créer un commit ? Prends l'habitude de faire tes commits après une fonction importante. Ça pourra aussi te permettre de mieux structurer ton code.
Ce qui est bien avec git c’est que l’on peut naviguer de commit en commit sur notre timeline.
Cette timeline, on peut la checker avec la commande git log.
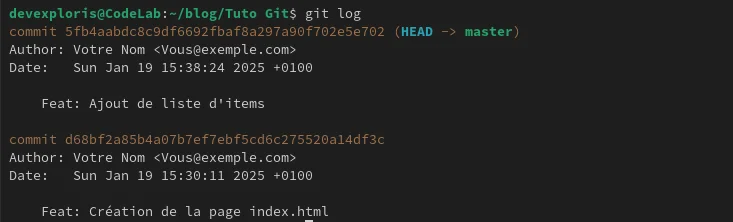
On y retrouve le nom de l’auteur du commit, la date et le commentaire. (Pour l'exemple je n'ai pas changé l'auteur par défaut).
Si je veux revenir en arrière, je copie le sha du 1er commit et je fais la commandegit checkout monSha .

git checkout c’est la base de la navigation dans les commits et dans les branches.
HEAD, c'est comme un pointeur qui montre où tu te trouves dans l'historique de ton projet.
Quand tu fais git checkout monSha, HEAD se déplace pour pointer sur le commit correspondant. Si HEAD n'est pas sur la branche principale ou la plus récente, on dit qu'il est "détaché". Cela te permet de naviguer dans l'historique sans modifier la version actuelle du code.
Lorsque HEAD est détaché, les modifications que tu fais ne sont pas attachées à une branche. Si tu veux sauvegarder ces changements, il faudra créer une nouvelle branche (on le voit juste après !)
Regardons à présent notre IDE, on s’aperçoit que notre liste d’Items à disparu.
On peut ainsi sans perdre son travail, basculer de commit en commit et checker différents points de son code, effectuer des modifications même si cela fait plusieurs jours que la sauvegarde a été effectuée.
Si on veut revenir au commit le plus récent de notre timeline, il suffit de faire un git checkout nomDeTaBranche .
ici : git checkout master .

Nous voila revenus à notre point le plus récent de notre repository.
Déjà petite précision, c’est tout à fait normal que si c’est ton premier repository, tu sois largué. Les termes, l’utilisation du C.L.I … c’est nouveau et un peu difficile. On verra un tout petit peu plus tard qu’avec GitHub c’est plus visuel (et il y a plein d’extensions pour t’aider dans les commandes).
Pour le moment retiens :
-
git add .
-
git commit -m "Commentaire de ton commit"
-
git log pour visualiser la liste des commits
-
git checkout shaDuCommit (ou de ta branche)
Se déplacer dans les commits d’une même branche c’est pas mal pour explorer mais c’est un peu dangereux (car Head est détaché et donc on ne change pas forcément une version à jour du code).
Si on veut faire de gros changements, le mieux c’est de créer une branche qui sert à la feature. Par exemple on va ajouter une page backToTheFutur.html mais avant, on va créer une nouvelle branche à l’aide de la commande :
git checkout -b nouvelleBranche .
-b pour "je crée une nouvelle branche et place moi dessus".

On est donc sur notre nouvelle branche et on va créer une seconde page html.

On sauvegarde (tu connais la musique) :
git add .
git commit -m "Feat: Ajout de la seconde page"

Si tu es un peu perdu dans les branches et les commits, fais un petit git status pour te repérer :

Ce que l’on a fait dans "nouvelleBranche" ne concerne que cette branche. Notre branche Master qui est la branche principale n’est pas impactée par les changements initiées sur la nouvelle branche.
Par conséquent je peux coder sans risque sur "nouvelleBranche", je ne modifie pas Master.
Par contre, à un moment donné, je vais devoir faire rejoindre master à nouvelleBranche (puisque nouvelleBranche sera plus avancée que master). Une fois que je suis satisfait de mon travail, je vais fusionner ma nouvelleBranche à ma branche master.
On se place alors dans master :
git checkout master .
(à présent la seconde page html a disparu puisque nous sommes passés de la nouvelle branche à master et que la seconde page se trouve dans nouvelleBranche).
Ensuite git merge nouvelleBranche .
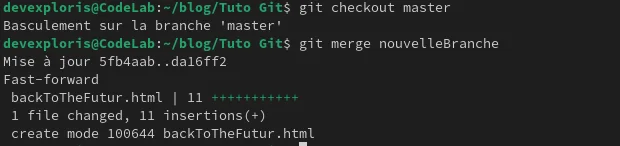
Lors d’un git merge, si des modifications incompatibles existent entre les branches, Git te signalera un conflit et tu devras ouvrir tes fichiers, résoudre le conflit, puis valider la résolution avec un nouveau commit (git add ., git commit -m "résolution conflit merge …").

Si tu n’as plus rien à faire sur ta branche nouvelleBranche alors tu peux la supprimer pour que ce soit plus propre dans ton repo à l’aide de la commande :
git branch -d nouvelleBranche
-d pour delete.

Tout ce que l’on a fait ici, c’est en local sur notre machine. Le but va être d’externaliser tout ça pour sauver son travail dans le cloud et pouvoir être plus serein si notre machine rend l’âme subitement.
Petite précision, Git peut être utilisé uniquement en local, rien d’obligatoire à envoyer son code ailleurs que sur sa machine, c’est juste plus sécurisant et forcément obligatoire pour le travail en collaboration).
On va donc se rendre sur GitHub (ou le site de ton choix en matière de version de code) (moi c’est Gitea) et on va créer un repository distant.
Tu cliques sur le "+" en haut de ta page et tu fais "new repository". Tu donnes un nom à ton repo, tu choisis si il doit être privé ou public et tu fais "create repository".
Ensuite tu devrais arriver sur une page ressemblant à ça :
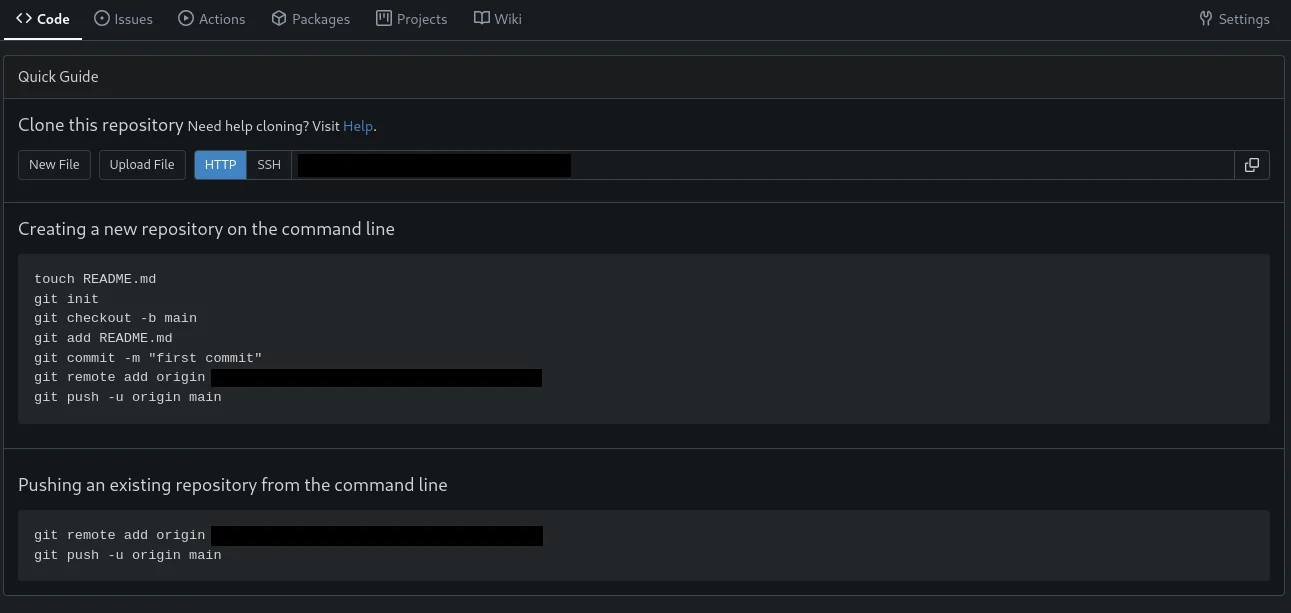
Cette page c’est ton repository distant. Quand tu crée un repo distant, GitHub va te proposer soit de créer ton repo local avec le premier paragraphe de code, soit juste de lier ton repo local et ton repo distant dans le cas où ton repo local est déjà existant (comme ici car on a déjà fait un git init au tout début du tuto).
Si tu as suivi mon tuto SSH, tu peux switcher HTTP(S) vers SSH puis copier la première ligne du second paragraphe de code git remote add origin tonUrl .
Puis une fois que tu as fais cela, tu fais la seconde partie :git push -u origin master (ici Gitea initialise main mais nous on a commencé le tuto avec master)
(tu entres tes identifiants ou en SSH tu n’as rien à rentrer)
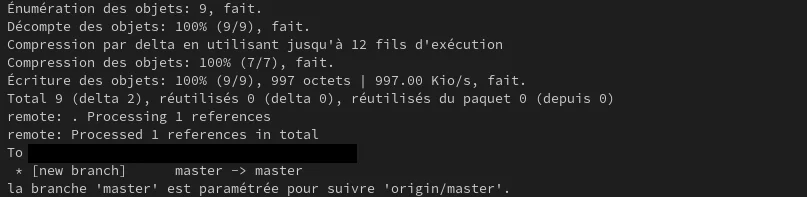
Maintenant tu peux actualiser ta page GitHub et tu devrais voir quelque chose comme ça :
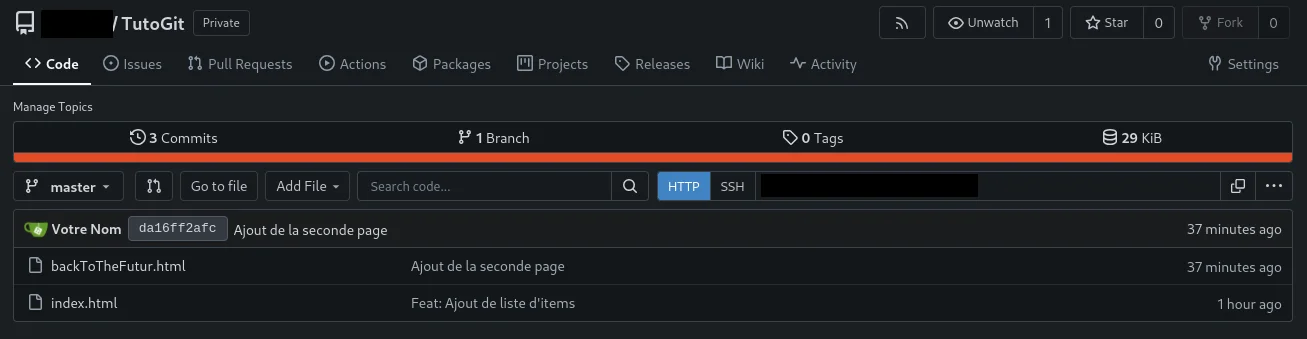
Tu peux t’amuser à explorer maintenant ton repo de manière graphique.
Il faut savoir que maintenant tu as un repo local (ton PC) et ton repo distant (GitHub).
Pour envoyer ton code maintenant que ton repo local est lié avec Github, tu as juste à faire git push après ton git commit -m "".
ça enverra directement le commit de ta branche sur GitHub.
Quand tu travailleras sur des projets en équipe, tu pourras aussi être amené à utiliser git fetch et git pull qui te permettront de mettre à jour ton repo local depuis ton repo distant.
git fetch va récupérer les données de ton repo distant mais ne va pas les appliquer sur ta branche tandis que git pull récupère ET fait un merge dessus.
Il y a beaucoup de commandes mais familiarise toi avec celles-ci pour dégrossir le mastodonte GIT/GitHub.
Et là petit moment sécurité. Si tu push ton code en ligne, ça veut dire que tes fichiers sont en ligne (ouais … j’enfonce une porte ouverte là). Mais ça veut dire que potentiellement, quelqu’un de malveillant peut aussi lire tes fichiers et si ils contiennent des mots de passes, de clés API … c’est dangereux. Quand tu push ton code, tu dois t’assurer que ton code ne contient pas de mot de passe en clair, de fichiers de configuration contenant des URLs sensibles etc …
Pour éviter ce genre de problème, tu peux créer un fichier .gitignore et y inclure les fichiers que tu ne souhaites pas à l’intérieur.
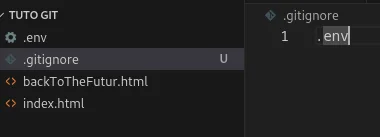
Ici j’ai inclus le fichier .env (qui correspond en général à des fichiers de configuration où des données secrètes peuvent être écrites.
Avec le .gitignore, j’ai dis "lors des git add ne mets pas le .env dans le versionnage".
Comme ça les infos sensibles, je les garde en local.
Tu peux aussi ajouter un readme.md à la racine de ton projet afin d’écrire ce que ton projet fait, à qui il est destiné, comment l’installer sur sa machine etc … (ça te servira aussi à ton toi du futur quand dans 6 mois tu reviendras sur ton projet) et c’est visible depuis github.

Voici un récapitulatif :
-
git add . : ajoute tous les fichiers modifiés ou nouveaux à l’index.
-
git commit -m "Mon message de commit" : enregistre les modifications avec un message descriptif.
-
git checkout : permet de naviguer entre commits ou branches.
-
git branch : affiche la liste des branches.
-
git checkout -b nomDeTaBranche : crée une nouvelle branche et s’y déplace.
-
git merge : fusionne une branche avec une autre.
-
git branch -d nomDeTaBranche : supprime une branche.
Je pense qu’on a dégrossi pas mal le concept du versionning.
Les exemples sur ce tuto sont relativement simples, le but n’était pas de te submerger de code mais de te permettre de mieux appréhender Git.
Dès à présent commence à utiliser les commandes ! Ton toi du futur t'en remerciera !